
Near both, on neither: why single-vector search fails high-intent queries
A personal experiment, written up on my own time. The opinions here are mine, not my employer's.
A buyer asks an AI assistant a simple-sounding question:
"What's a good CRM for a GDPR-compliant team that integrates with Salesforce?"
Two requirements. Both concrete. The assistant answers with confidence - and recommends a tool that is GDPR-adjacent, integrates with a dozen things, and connects to HubSpot but not Salesforce. It is near both requirements and on neither. The buyer, who was ready to sign, quietly closes the tab.
This is not a prompt-engineering problem or a hallucination. It is a retrieval problem, and it has a precise mechanical cause. Before an answer engine writes a single word, it retrieves candidates - and the dominant way it does that is by averaging everything it knows about each candidate into one point in space. Averaging is exactly the wrong operation when a buyer states two facets that must both hold.
Martin Spišák called this the lineup problem in the context of recommender systems, using an NBA example: ask for a lineup that is both elite on defense and elite from three, and a single-vector model hands you players who are pretty good at both instead of the specialists who are elite at each. I'm not a huge sports guy, but I use a lot of SaaS products, so I wanted to recreate his experiment in a domain I actually know and see whether his findings held. They do. The single dense vector that powers most modern retrieval cannot reliably keep multi-facet conjunctions intact. Late interaction can. What follows is the experiment and the honest numbers.
The problem: one vector, one point, one average
Modern retrieval mostly runs on dense embeddings. The lineage is the two-tower recommender: encode the query into a vector, encode each candidate into a vector, rank by cosine similarity. It is fast, it scales to billions of items with an approximate-nearest-neighbor index, and it captures semantic similarity that keyword search misses. The LLM era added a shortcut on top - "describe what you want in natural language, embed the description, retrieve the nearest documents" - but the mechanism underneath is unchanged. Every candidate is compressed to a single point.
That compression is the whole problem. A SaaS tool is not one thing. It is a category, a positioning, a description, and a list - often 15 to 30 integrations, plus a handful of buyer segments it serves. Squeeze all of that into one 1,024-dimensional vector and every attribute gets averaged against every other attribute. The integration a buyer actually asked about is one token's worth of signal, diluted across two dozen others. The compliance posture the buyer needs is a faint direction competing with category, price, and tone.
For a generic query - "a good CRM" - the average is fine, because the average is what you asked for. For a compound, high-intent query - "GDPR-compliant CRM that integrates with Salesforce" - the average is a confidently wrong answer, because no single point can be simultaneously extreme on two nearly independent axes and still sit near the query. This is where purchase intent is highest and where single-vector retrieval is weakest.
Late interaction: keep a vector per token
The alternative is late interaction, introduced by ColBERT (Khattab & Zaharia, 2020). Instead of collapsing a document to one vector, ColBERT keeps one vector per token. Scoring uses MaxSim: for each query token, find its best-matching document token, then sum those best matches. Nothing is averaged away before the query arrives. If the buyer's query has a token for "Salesforce" and a token for "GDPR," each can lock onto the specific document token that satisfies it - the buried integration name, the compliance phrase - independently. The document does not have to be near the query on average; it has to contain evidence for each facet somewhere.
The historical objection to late interaction was cost. One vector per token means far more storage and a heavier scoring step than a single dot product. That objection is fading. MUVERA (Google, 2024) shows how to compress multi-vector representations into fixed-size encodings that retrieve with single-vector machinery and MaxSim-quality results, and a wave of efficient late-interaction models has made per-token indexing practical at scale. What was "too expensive to consider" is now a live engineering choice.
Why this matters for AI-search visibility
Answer engines - ChatGPT, Perplexity, Google's AI mode, the assistant embedded in your buyer's workflow - do not read the whole internet before answering. They retrieve a small candidate set, then write over it. If your brand's page is compressed to a single averaged vector and the buyer asks a two-facet question, your page can be relevant on both facets and still lose to a page that is closer on average.
Concretely: you rank fine for "best CRM" - the generic prompt where the average works. You vanish on "GDPR-compliant CRM that integrates with Salesforce" - the compound, bottom-of-funnel prompt where the buyer has a credit card out. The retrieval layer that decides which brands even reach the model's context window is doing the averaging, and the averaging is deleting exactly the specificity that high-intent buyers ask for. Generative engine optimization is, in large part, a fight against this compression.
One honest caveat before the numbers: production answer engines increasingly hybridise - lexical, dense, and rerankers stacked together - and a hybrid stack would recover the buried-integration case that pure dense retrieval misses below. So this is not a claim that you are invisible everywhere; it is that the dense component, wherever it sits in the stack, applies exactly this averaging pressure - and the more a system leans on single-vector recall, the more the compound, high-intent query is where you quietly drop out.
The setup
I built a small, self-contained information-retrieval experiment on a martech tools catalog and ran three retrievers against three query profiles.
The catalog. 1,200 SaaS/martech tools across 10 categories. Each tool has a name, a category, a short description, a list of integrations (median 22 per tool, ranging 15–30), and a set of buyer segments. Only the name, category, description, and integrations are rendered into the text that retrievers see; the segments are held back as structured relevance labels (more on that below).
The three query profiles, each designed to isolate a failure mode:
- Profile 1 - "a tool that integrates with {X}." A single literal integration name (e.g. ConvertKit) that appears verbatim in the target tool's text - but buried among ~22 others. Relevant tools are a median 3.6% of the catalog.
- Profile 2 - "a tool for {concept} teams." A semantic segment (e.g. gdpr, remote-first) whose canonical term never appears literally in any tool's text. Tools express the concept only through surface realizations - a GDPR tool says "compliant with European data regulations" or "EU data residency available," never "GDPR." Relevant tools are a median 7.0% of the catalog. This is a pure semantic-matching test with nothing to lexically grab.
- Profile 3 - the conjunction. "a tool for {concept} teams that integrates with {X}." Both facets must hold. Relevant sets are tiny - a median 0.3% of the catalog - because the intersection of two sparse conditions is sparse. This is the stress test and the whole point.
The three retrievers:
- BM25 - classic lexical/sparse retrieval.
- Dense - a single embedding vector per document, using Qwen3-Embedding-0.6B.
- Late interaction - one vector per token with MaxSim scoring, using Iso-ModernColBERT.
A caveat on the comparison: these are three different systems, not one model in three modes, so this is not a perfectly controlled ablation. It is worth being clear which way the imbalance cuts, though - the dense model (0.6B parameters) is the larger of the two, so late interaction's edge below is not a case of throwing a bigger model at the problem. The single-vector bottleneck is the handicap here, not model scale.
The metrics. MRR (mean reciprocal rank - how high the first relevant result lands, a top-1 quality signal) and Recall@R (of the R truly-relevant items, how many appear in the top R - a coverage signal). I evaluated over 30 Profile-1 queries, 28 Profile-2 queries, and 30 Profile-3 queries.
Provenance - read this. The catalog is semi-synthetic. The tool records are generated deterministically from a fixed seed, but seeded from real taxonomies: 350+ real integration names and 28 real B2B-SaaS positioning concepts. Relevance is rule-based - a tool is relevant to a query if and only if it satisfies the query's structured condition (the integration is in its integration list; the concept is in its segment set; both, for Profile 3). No model decides correctness; the ground truth is exact set membership, so the evaluation is free of any subjective relevance judgment. I went looking for a clean public SaaS dataset at the scale I needed (1,000+ named tools with structured integrations and positioning) and did not find one, which is why the backbone is synthetic. The failure modes it reproduces are the real ones.
Here is the full result table. Every number below is drawn from it.
| method | P1 MRR / R@R | P2 MRR / R@R | P3 MRR / R@R |
|---|---|---|---|
| bm25 | 1.00 / 0.92 | 0.25 / 0.09 | 0.19 / 0.11 |
| dense | 0.29 / 0.08 | 0.53 / 0.14 | 0.08 / 0.02 |
| late | 1.00 / 0.92 | 0.37 / 0.15 | 0.32 / 0.14 |
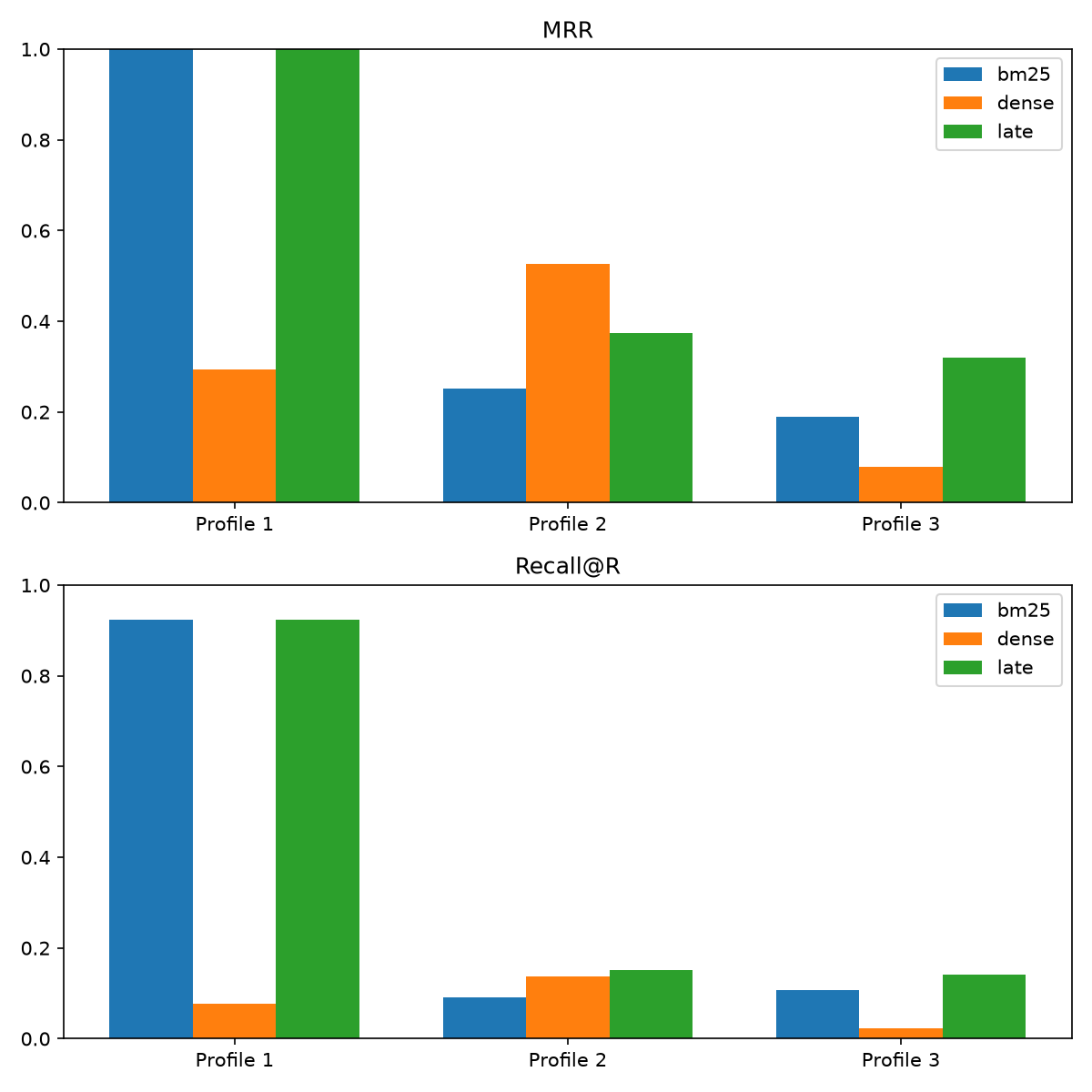
Profile 1: the single dense vector breaks, textbook
Profile 1 asks for one literal integration, buried among two dozen. This is the cleanest demonstration in the experiment.
- BM25: 1.00 MRR, 0.92 recall. The integration name is right there in the text; lexical match nails it.
- Late interaction: 1.00 MRR, 0.92 recall. Identical. A query token for the integration name locks onto the exact document token via MaxSim. The other 21 integrations don't dilute it, because nothing was averaged.
- Dense: 0.29 MRR, 0.08 recall. It breaks. The queried integration is one token averaged among ~22 in the document vector. Its signal is diluted below the noise of category, description, and every other integration, so the single vector simply cannot find it. The first relevant result lands around rank 3 on average, and coverage collapses to 8%.
This mirrors the original lineup result almost exactly - Spišák's dense baseline scored around 0.30 on the analogous single-attribute query. A single embedding vector is not a lookup table; it is a smoothed summary, and a buried literal is precisely what a smoothed summary loses.
Profile 2: the honest one - dense wins top-1, late wins coverage
Profile 2 flips the terrain. There is no literal term to match - a GDPR tool never says "GDPR" - so this is a pure semantic test. The results here are nuanced, and I'm not going to paper over them.
- BM25: 0.25 MRR, 0.09 recall. It breaks, as it must. There is nothing to lexically match; "gdpr" appears nowhere in the documents. Sparse retrieval has no purchase on a concept expressed only through paraphrase.
- Dense: 0.53 MRR, 0.14 recall. The best top-1 score of any method on this profile. This is the case dense embeddings are built for: mapping "gdpr" and "compliant with European data regulations" into nearby regions of semantic space. A single vector is very good at surfacing one strongly on-concept result.
- Late interaction: 0.37 MRR, 0.15 recall. Lower MRR than dense, but higher recall.
Read this exactly as Spišák framed the analogous case. A single dense vector can point you at one good on-concept result - hence the decent MRR - but it misses the rest of the relevant set, because once it has committed to the average concept direction it has spent its capacity. Late interaction trades a little top-1 sharpness (0.37 vs 0.53 MRR) for better coverage of the full relevant set (0.15 vs 0.14 recall). Late interaction does not dominate Profile 2, and I won't claim it does. For "find me one" queries, a single dense vector is a perfectly good tool. The story changes when "one" is not enough - and when both facets have to hold.
Profile 3: the conjunction - the payoff
Profile 3 is the query that matters commercially: "a tool for {concept} teams that integrates with {X}." Both facets, high intent, tiny relevant set. This is where the single vector's capacity ceiling bites hardest, and it breaks both baselines:
- BM25: 0.19 MRR, 0.11 recall. It can match the integration name lexically but is blind to the concept, so it drags in tools that integrate with {X} but serve the wrong segment.
- Dense: 0.08 MRR, 0.02 recall. The worst score in the entire experiment. Forced to average a buried literal integration and a paraphrased concept into one point, the single vector satisfies neither. It is near both requirements and on neither - the confidently-wrong recommendation from the hook, quantified.
- Late interaction: 0.32 MRR, 0.14 recall. Best on both metrics. Separate query tokens lock onto the integration evidence and the concept evidence independently, so a document only scores high when it carries evidence for both.
The margins are more modest than the original article's - Spišák's late-interaction method scored near 1.00 on the analogous conjunction, where mine lands at 0.32 MRR. My catalog is harder and noisier, and I report what I measured. The ordering is the point. On the conjunction that represents real buyer intent, late interaction is best on top-1 and best on coverage, and both single-representation baselines fall apart.
Here is a real top-3 for one Profile-3 query, straight from the run data. The query: "a tool for multi-language teams that integrates with Bitbucket" - a conjunction with only two truly-relevant tools in the entire 1,200-item catalog (0.17%).
| rank | BM25 | Dense | Late interaction |
|---|---|---|---|
| 1 | Driftio202 ✗ | Beaconlabs848 ✗ | Quillbase560 ✓ |
| 2 | Emberloop534 ✓ | Forgeworks67 ✗ | Emberloop534 ✓ |
| 3 | Atlasbase927 ✗ | Emberly110 ✗ | Novaio9 ✗ |
Late interaction surfaces both relevant tools in its top 3. BM25 finds one but ranks it second, behind an irrelevant tool it matched on the integration alone. Dense finds neither - its top 3 is three tools that are near the query on average and satisfy the conjunction not at all. When a buyer types the compound question, this is the difference between showing up and disappearing.
Why this happens: the capacity ceiling
The intuition - "one vector can't hold two independent facts" - has a formal spine. A recent result on the representational capacity of single-vector embeddings - Weller et al.'s "On the Theoretical Limitations of Embedding-Based Retrieval" (Google DeepMind, ICLR 2026) - shows that for a fixed dimensionality d, there is a hard ceiling on the number of distinct relevance patterns the vectors can encode: some sets of query-document relevance judgments are simply not realizable by any assignment of d-dimensional vectors, no matter how the model is trained. Conjunctions of independent facets are exactly the kind of pattern that blows past the ceiling first - the number of facet-combinations grows combinatorially while d stays fixed. (This is a cited result, not mine; my experiment is the empirical shadow it casts.)
Late interaction sidesteps the ceiling by refusing to compress. Keeping one vector per token means the representation grows with the document, so no facet has to share a dimension budget with every other facet. The evidence for "Salesforce" and the evidence for "GDPR" live in different tokens and are scored separately by MaxSim. There is no averaging step in which one erases the other. That is the entire mechanical difference, and Profiles 1 and 3 are what it buys you.
This is not about SaaS tools
Swap the nouns and it's the problem I spend my working hours on.
The catalog is your brand pages, competitor catalogs, and product feeds. The queries are buyer prompts typed into answer engines. The averaging that buried an integration name among 21 others is the same averaging that buries a specific capability, a specific integration, a specific compliance posture inside a single embedding of a dense landing page. A page that tries to be about everything becomes, to a single-vector retriever, about nothing in particular - near the average of its topics, on none of them.
The generative-engine-optimization takeaway follows directly: structure content so each facet keeps its own evidence instead of blurring into one averaged page. A dedicated, clearly-worded section for each integration; explicit, plainly-stated compliance and segment claims; product data where each attribute is its own field rather than a paragraph of adjectives. You cannot control whether an answer engine retrieves with a single vector or with late interaction - but you can make sure that when it retrieves, the specific evidence a high-intent buyer asked for is present, prominent, and not diluted into the mean. The brands that win the compound, bottom-of-funnel prompt are the ones whose content hasn't been pre-averaged into oblivion before the model ever sees it.
Close
A single dense vector is a good default and a poor absolutist. Across three profiles, it was the only method that broke on the literal-integration query (Profile 1) and the conjunction (Profile 3), while genuinely winning the pure-semantic top-1 case (Profile 2). BM25 broke on both concept profiles. Late interaction was the only method that never broke: strong everywhere, best on the conjunction that carries real purchase intent. That is the honest, load-bearing claim.
This is the part I keep coming back to. AI-search visibility is decided at the retrieval layer, and the retrieval layer is where facets go to be averaged away. Knowing when that averaging helps - and when it quietly deletes your best buyers - feels like the difference between measuring visibility and actually improving it.
Under the hood: the whole thing - catalog builder, query generator, the three retrievers, and the evaluation harness - is on GitHub, small and self-contained, and relevance is rule-based structured-field membership, so every number here traces to exact set membership rather than a judgment call. Adapted from Martin Spišák's "The lineup problem: an opportunity for late interaction in RecSys," repurposed from his NBA example to AI-search visibility.